
MACHINE LEARNING
Machine Learning (ML) là “trái tim” của trí tuệ nhân tạo hiện đại và là động cơ thúc đẩy các quyết định kinh doanh thông minh. Khóa học này được thiết kế để đưa bạn vào vai trò của một người giải quyết vấn đề, có khả năng biến dữ liệu lịch sử thành những dự báo giá trị cho tương lai: từ việc dự đoán khách hàng nào sẽ rời bỏ dịch vụ, ước tính giá bất động sản, đến phân loại sản phẩm. Đây không chỉ là một khóa học về thuật toán, mà là hành trình giúp bạn kết nối bài toán kinh doanh với giải pháp kỹ thuật, tạo ra tác động thực tiễn và có thể đo lường được.
Chương trình sẽ hướng dẫn bạn xây dựng một pipeline Machine Learning hoàn chỉnh, với thư viện scikit-learn là công cụ trung tâm. Bạn sẽ bắt đầu từ bước quan trọng nhất là Feature Engineering để biến đổi và tạo ra các đặc trưng mạnh mẽ từ dữ liệu thô. Sau đó, bạn sẽ đi sâu vào hai nhánh chính của ML: Học có giám sát, với các thuật toán hồi quy và phân loại kinh điển; và Học không giám sát để khám phá các cấu trúc ẩn qua thuật toán phân cụm và giảm chiều dữ liệu. Khóa học còn trang bị cho bạn các kỹ thuật Ensemble Methods như Random Forest và Gradient Boosting để xây dựng những mô hình có độ chính xác vượt trội.
Thời lượng: 33h

KẾT QUẢ ĐẠT ĐƯỢC

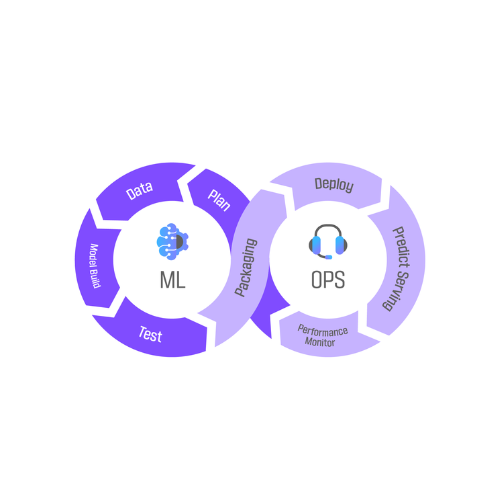
NẮM VỮNG QUY TRÌNH TRIỂN KHAI MACHINE LEARNING
Hiểu rõ từng bước trong vòng đời dự án ML, từ xác định bài toán kinh doanh, chuẩn bị dữ liệu, xây dựng, đánh giá đến tối ưu hóa mô hình.

THÀNH THẠO CÁC THUẬT TOÁN ML PHỔ BIẾN
Ứng dụng thành công các thuật toán Regression, Classification, Clustering, PCA vào các bài toán dự báo, phân loại và phân nhóm .

KỸ NĂNG FEATURE ENGINEERING CHUYÊN NGHIỆP
Có thể tự tin lựa chọn, biến đổi và xây dựng đặc trưng mới nhằm tăng hiệu suất mô hình và khai thác tối đa giá trị dữ liệu.

ĐÁNH GIÁ & CHỌN MÔ HÌNH TỐI ƯU
Hiểu và áp dụng linh hoạt các chỉ số MAE, RMSE, Accuracy, Precision, Recall, F1-score, ROC-AUC để đánh giá, so sánh các mô hình.

THỰC HÀNH DỰ ÁN THỰC TẾ VỚI DỮ LIỆU DOANH NGHIỆP
Trực tiếp triển khai pipeline Machine Learning trên dữ liệu khách hàng, bán hàng, tài chính thực tế – tạo giá trị ngay khi kết thúc khóa học.


Yêu cầu tiên quyết:
-
- Thành thạo Pandas và Python từ khóa trước.
- Hiểu cơ bản về xác suất thống kê và các khái niệm dữ liệu.
Nội dung khóa học
1. Nền tảng Machine Learning và Chuẩn bị Dữ liệu
- Tổng quan về Vòng đời Dự án Machine Learning:
- Khái quát quy trình End-to-End: từ việc xác định bài toán kinh doanh, thu thập dữ liệu, huấn luyện mô hình, đánh giá, cho đến triển khai và giám sát.
- Vai trò của kỹ sư AI/ML trong từng giai đoạn và các thách thức thường gặp.
- Feature Engineering – Kỹ thuật biến đổi và lựa chọn đặc trưng:
- Hiểu tại sao Feature Engineering là một trong những bước quan trọng nhất, quyết định đến hiệu năng của mô hình.
- Kỹ thuật xử lý biến phân loại (Categorical Features): Mã hóa One-Hot Encoding và Label Encoding, phân biệt trường hợp sử dụng.
- Kỹ thuật xử lý biến số (Numerical Features): Chuẩn hóa dữ liệu với StandardScaler và MinMaxScaler để các thuật toán hoạt động hiệu quả.
2. Các Mô hình Học có Giám sát (Supervised Learning)
- Các bài toán Hồi quy (Regression):
- Mục tiêu: dự đoán một giá trị liên tục (giá nhà, doanh số).
- Các thuật toán: Linear Regression, Polynomial Regression.
- Các độ đo đánh giá: MAE, MSE, RMSE, R-squared.
- Các bài toán Phân loại (Classification):
- Mục tiêu: dự đoán một nhãn rời rạc (email spam/không spam, khách hàng tiềm năng/không tiềm năng).
- Các thuật toán: Logistic Regression, Support Vector Machines (SVM), Decision Trees.
- Ma trận nhầm lẫn (Confusion Matrix) và các độ đo đánh giá: Accuracy, Precision, Recall, F1-Score, đường cong ROC-AUC.
- Phương pháp Ensemble – Sức mạnh của Mô hình Tập thể:
- Lý do kết hợp nhiều mô hình yếu lại có thể tạo ra một mô hình dự báo mạnh mẽ và ổn định hơn.
- Các kỹ thuật phổ biến: Bagging (Random Forest), Boosting (Gradient Boosting, XGBoost).
3. Các Mô hình Học không Giám sát (Unsupervised Learning)
- Tổng quan về Học không Giám sát:
- Mục tiêu: tự động khám phá các cấu trúc và quy luật ẩn trong dữ liệu mà không cần nhãn (labels).
- Các ứng dụng thực tế: phân khúc khách hàng, phát hiện bất thường, giảm chiều dữ liệu.
- Bài toán Phân cụm (Clustering):
- Thuật toán K-Means: tìm ra các nhóm (cụm) đối tượng có đặc điểm tương đồng.
- Thuật toán DBSCAN: phân cụm dựa trên mật độ, có khả năng phát hiện nhiễu (noise) và các cụm có hình dạng bất kỳ.
- Bài toán Giảm chiều dữ liệu (Dimensionality Reduction):
- Thuật toán PCA (Principal Component Analysis): giảm số lượng đặc trưng của dữ liệu mà vẫn giữ lại nhiều thông tin quan trọng nhất, giúp trực quan hóa và tăng tốc độ huấn luyện.
4. Tối ưu và Đánh giá Mô hình Nâng cao
- Kỹ thuật Đánh giá Mô hình Tin cậy:
- Đánh giá chéo (Cross-Validation): “tiêu chuẩn vàng” trong việc ước lượng hiệu năng thực sự của mô hình trên dữ liệu mới và tránh vấn đề overfitting (quá khớp).
- Phân tích các sai lầm của mô hình để có hướng cải thiện.
- Tinh chỉnh Siêu tham số (Hyperparameter Tuning):
- Phân biệt tham số (parameters) và siêu tham số (hyperparameters).
- Các phương pháp tìm kiếm bộ siêu tham số tốt nhất cho mô hình: Grid Search, Random Search.
- Xây dựng quy trình làm việc hoàn chỉnh (Pipeline):
- Kết hợp các bước tiền xử lý, feature engineering và mô hình thành một quy trình duy nhất, giúp tự động hóa và tránh rò rỉ dữ liệu (data leakage).
5. BÀI THỰC HÀNH CUỐI KHÓA: Dự án dự đoán churn hoặc giá bất động sản
- Yêu cầu chi tiết:
- Xử lý dữ liệu thực tế:
- Làm sạch, chọn đặc trưng, chuẩn hóa, encoding từ một tập dữ liệu khách hàng hoặc bất động sản thực tế.
- Xây dựng nhiều mô hình ML:
- Thực hiện train/test với các thuật toán đã học: Linear/Logistic Regression, Decision Tree, Random Forest, XGBoost (nếu đủ thời gian).
- Đánh giá so sánh hiệu năng các mô hình.
- Tối ưu hóa mô hình:
- Sử dụng GridSearchCV để tune tham số, chọn mô hình tốt nhất.
- Tránh overfitting qua kỹ thuật regularization, kiểm chứng mô hình bằng cross-validation.
- Trực quan hóa & báo cáo:
- Visual hóa kết quả: biểu đồ ROC, confusion matrix, biểu đồ giá thực tế vs. dự đoán…
- Chuẩn bị báo cáo tóm tắt: quy trình thực hiện, insight rút ra, đề xuất ứng dụng kết quả vào thực tế doanh nghiệp.
- Xử lý dữ liệu thực tế:








Bài viết liên quan
